Final Report
Introduction
This project aims to help enterprises and organizations to improve their customer feedback processing and management system and overall complaint resolution strategies. We had dived into relationships between all complaint information and make attempt to come up new ways to categorize complaints and new criteria for prioritize the processing order.
Findings
- Relationships between complaint information data are weak;
- Categorized complaint content texts base on product category is not proper and can’t cluster
Key insights
- We can categorize complaints simply base on processed complaint text.
- We can predict user’s sentiment base on complaint information.
Data Source
We used the Consumer Complaint Database from the Consumer Financial Protection Bureau (CFPB) to collect detailed information about consumer complaints related to financial products and services.
The Consumer Complaint Database serves as a central repository for complaints about financial products and services. It includes issues ranging from credit cards and loans to mortgages and bank accounts. Once the CFPB receives a complaint, it forwards the details to the respective company for resolution. Complaints are published in the database after the company responds or 15 days after submission, whichever comes first. The CFPB ensures the database is updated daily, making it a reliable and timely resource for tracking consumer issues in the financial sector.
Supervised Learning
Supervised learning involves training a model on labeled data. In the context of consumer complaints, supervised learning techniques can be applied to predict important outcomes, such as sentiment scores or complaint categories, based on various features. By utilizing labeled data, we can build models that help organizations like the CFPB or financial companies to automate the decision-making process, prioritize complaints, and improve overall complaint resolution strategies.
Regression analysis
Regression analysis is used to predict continuous outcomes based on independent variables. In this context, we applied regression techniques to predict the sentiment score of a complaint based on features such as product type, issue, and complaint tags. By understanding the relationship between these features and sentiment scores, financial institutions or the CFPB can better measure the emotional tone of complaints and determine their urgency or priority for resolution. A regression model can help automate the process of assessing complaints, ensuring that companies respond appropriately based on the predicted sentiment.
Since complaints are typically negative, we used the negative score as the predictor. The negative score ranges from 0 to 1, with higher values indicating stronger negative sentiment.
Based on several regression models, we conclude that tree-based regression models outperform linear regression. Among all tree-based models, whether default or tuned, the performance of Decision Tree, Random Forest, and Gradient Boosting models is very similar. However, considering the variability in real-world data and the randomness in our train-test split, we select the Random Forest model as our final choice. It performs well on both training and test data, and as an ensemble model, it presents strong consistency across different datasets.
The prediction result shows below:
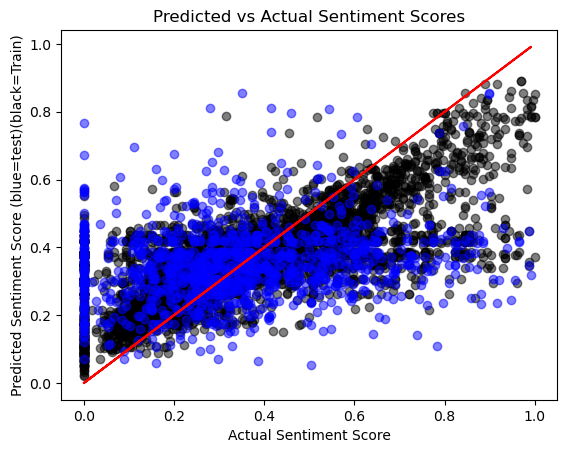
Classification Analysis
Classification techniques aim to categorize data into predefined classes or labels. For consumer complaints, classification models can be used to determine the category of a complaint based on features like the company involved, sentiment score, complaint amount, and narrative complaint length. This can help the CFPB or companies assess whether a complaint has been correctly categorized and identify potential misclassifications. By automating the classification process, organizations can streamline their complaint handling systems, ensuring complaints are routed to the appropriate department and addressed more efficiently.
For binary classification, the Random Forest classifier outperforms the Logistic Regression model.
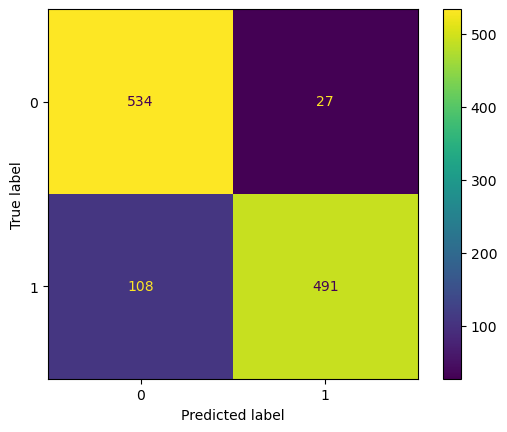
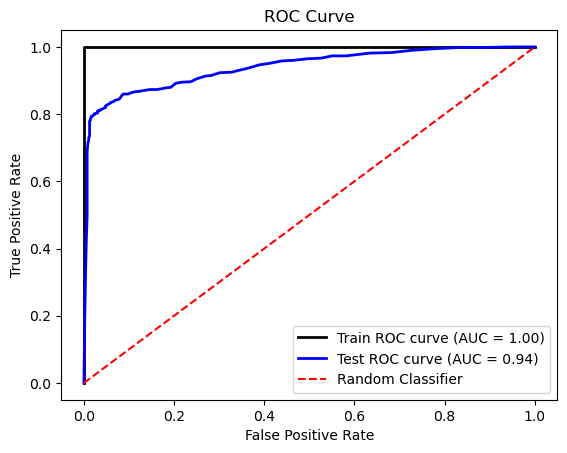
For multi-class classification, considering the imbalance in our dataset, we focus on the Weighted F1 score for the test dataset as the evaluation criterion. Based on this, we believe the One-vs-Rest model is the best choice. While the Random Forest model achieves perfect results on the training data, it may lead to undesired overfitting, making it less reliable for generalization.
The prediction result shows below:
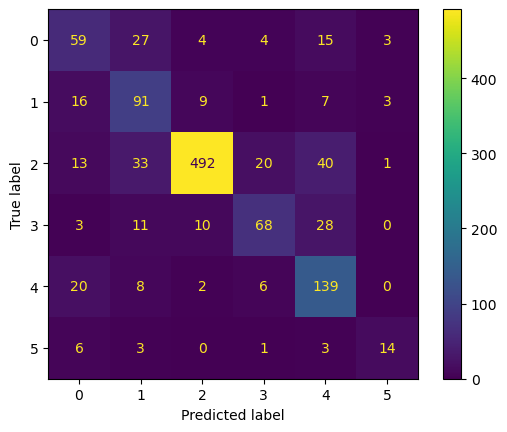
Unsupervised learning
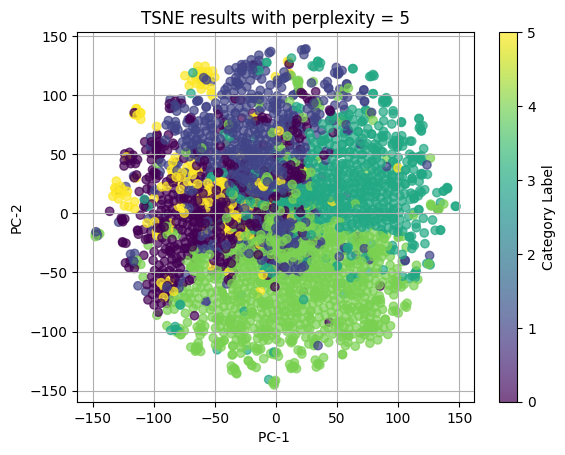
According to all dimentionality reduction parts and clustering parts, we can conclude that for our text data, TFIDF vectorization works a bit better than BERT embedding, t-SNE works better than PCA in visualization, KMeans method works well but definitely not DBSCAN. For other categorical data and numerical data, t-SNE works well in dimentionality reduction and hierarchical clusters well.
In conclusion to our topic, the product category doesn’t seem to have close relationship with users’ actual complaint content as shown in the plot below, or one of another assumption is that the product categories are too similar to each other and don’t have much difference, which may also misleading the users when submitting their complaint. The product category can’t categorize the complaints properly.
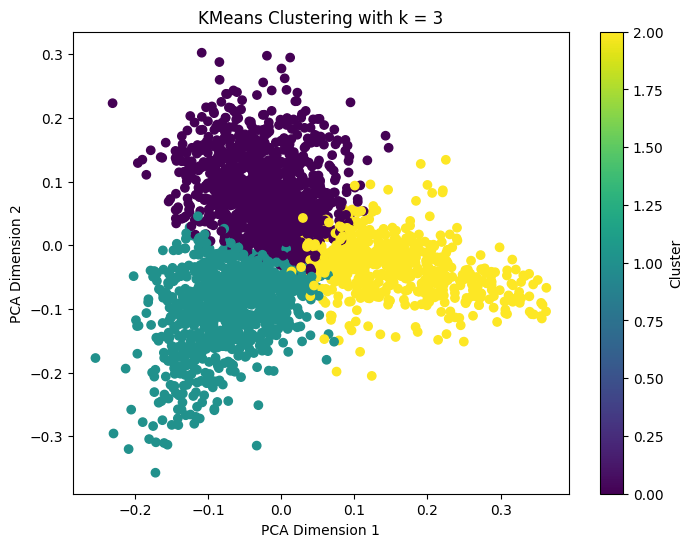
Base on our KMeans model results shown in the below image, we can see that there are different ways we can apply to form better categorization in order to enhance the efficiency of complaint handling. We now have the clusters, for further research, maybe we can dive into each clusters to specify each cluster’s topic.
Business Implications
Optimizing the channels for connecting enterprises with users and the strategies for dealing with negative news is conducive to establishing a better corporate image and achieving higher achievements in future corporate affairs
Conclusion
In the sight of the user, we think there are many ways for enterprises to better serve customer and satisfy user’s demands.